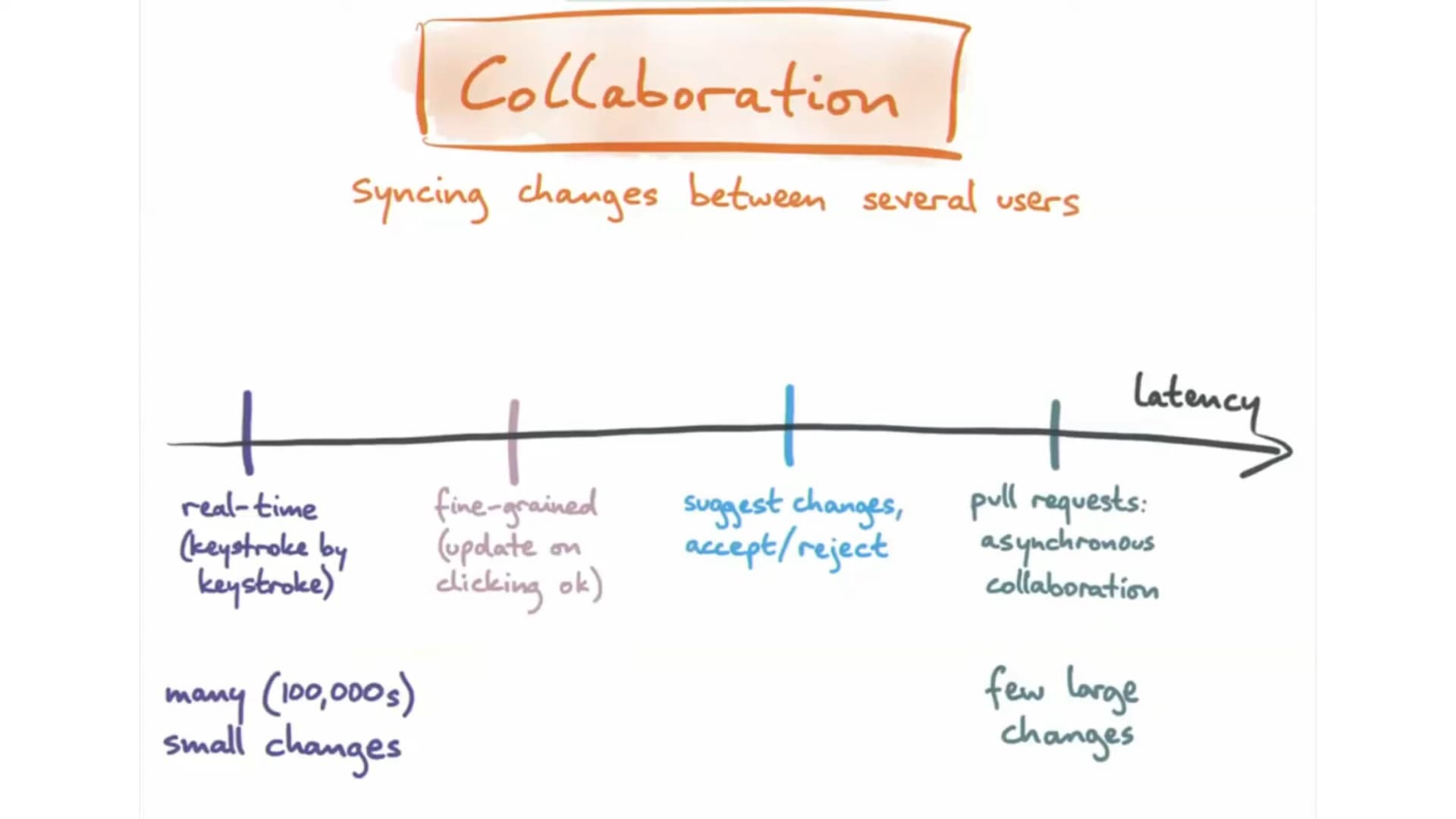
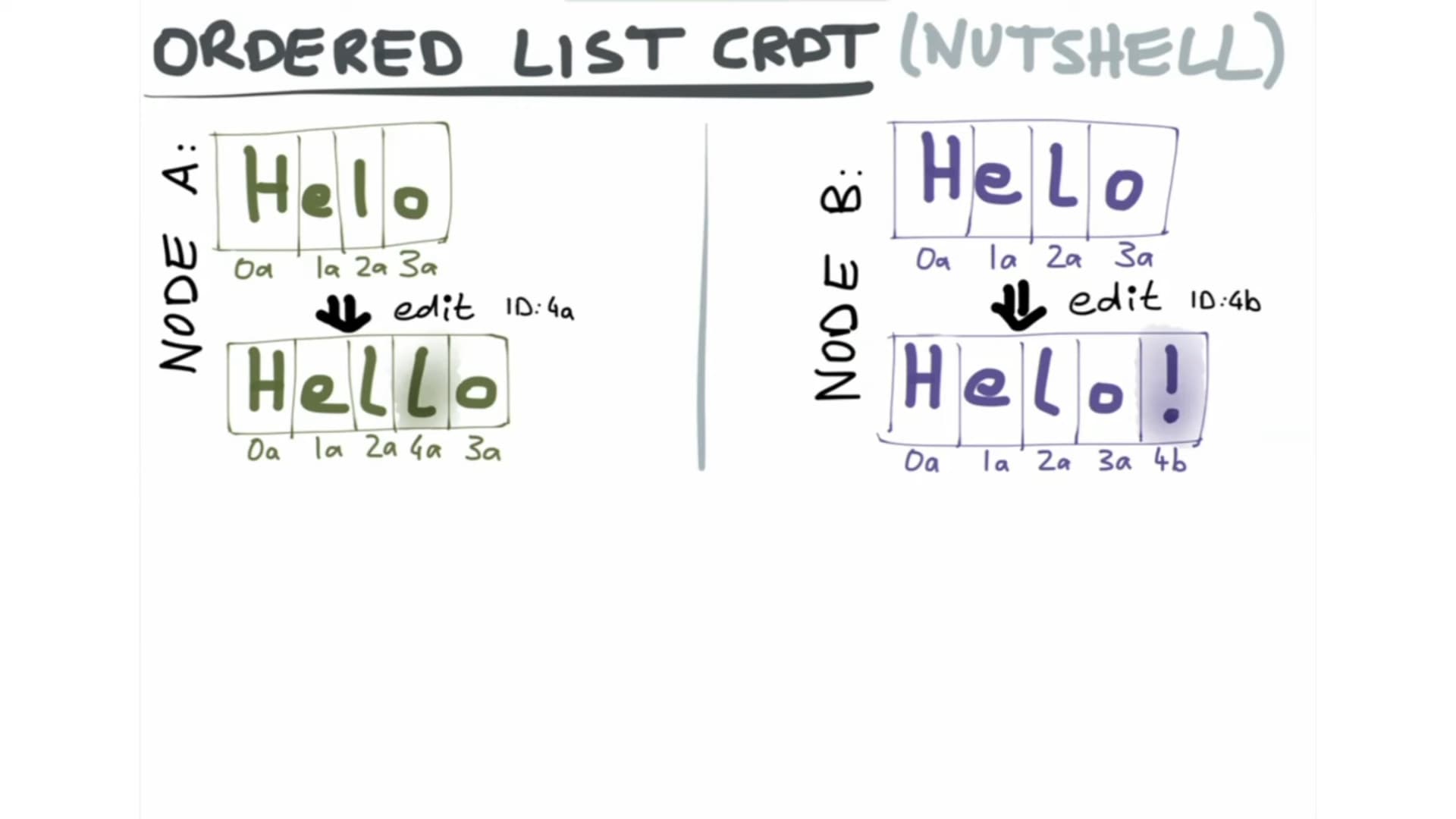
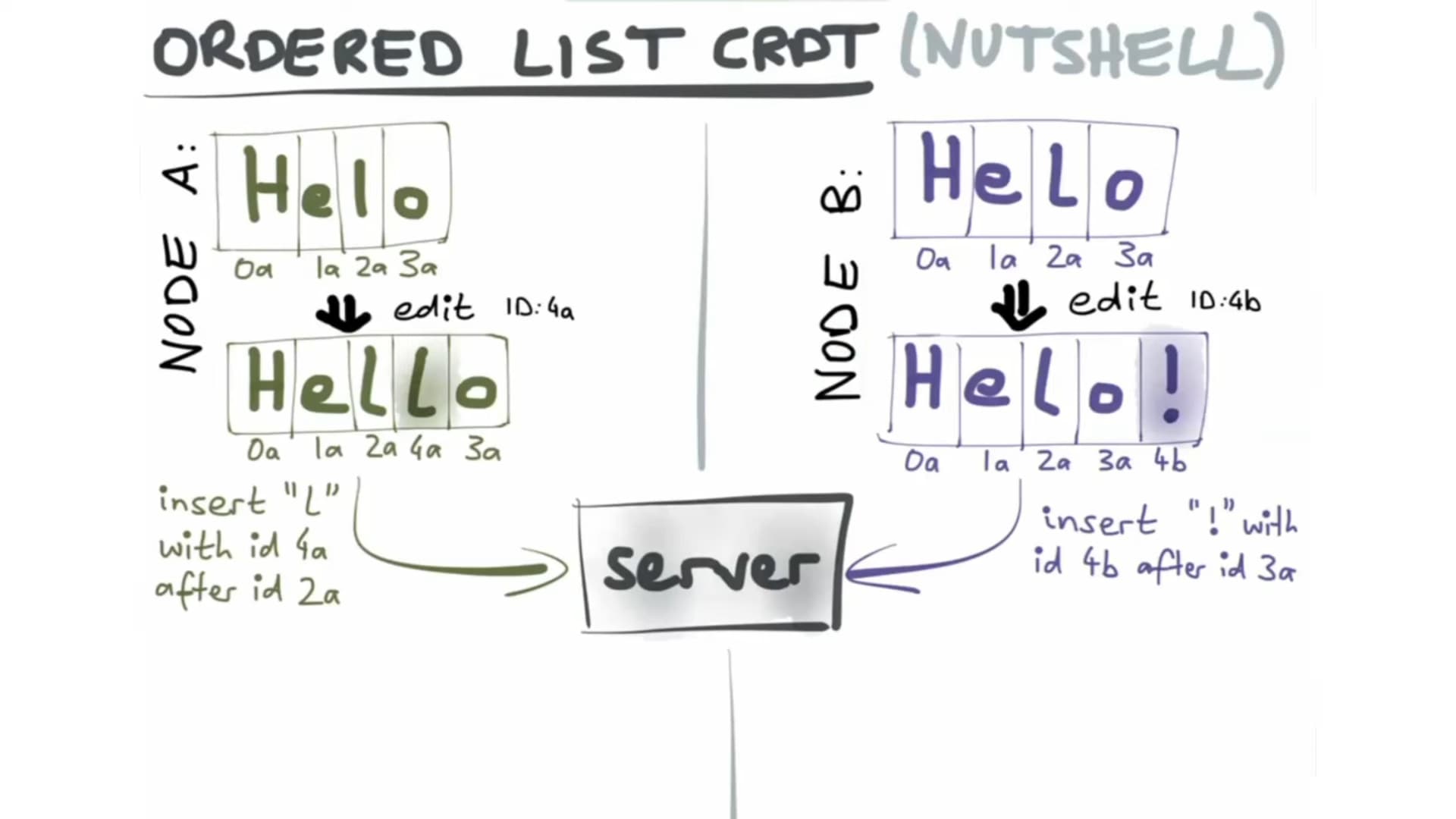
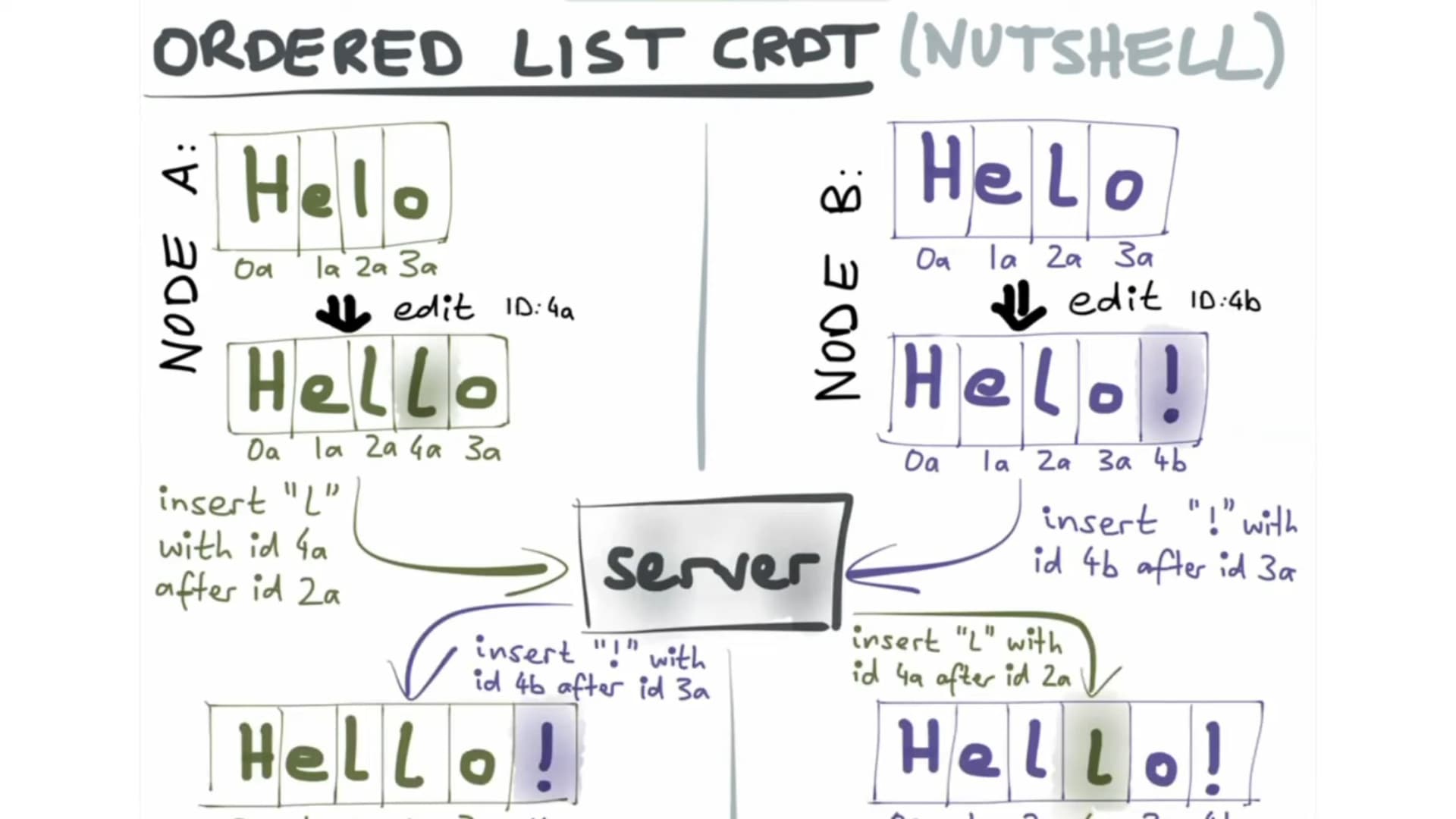
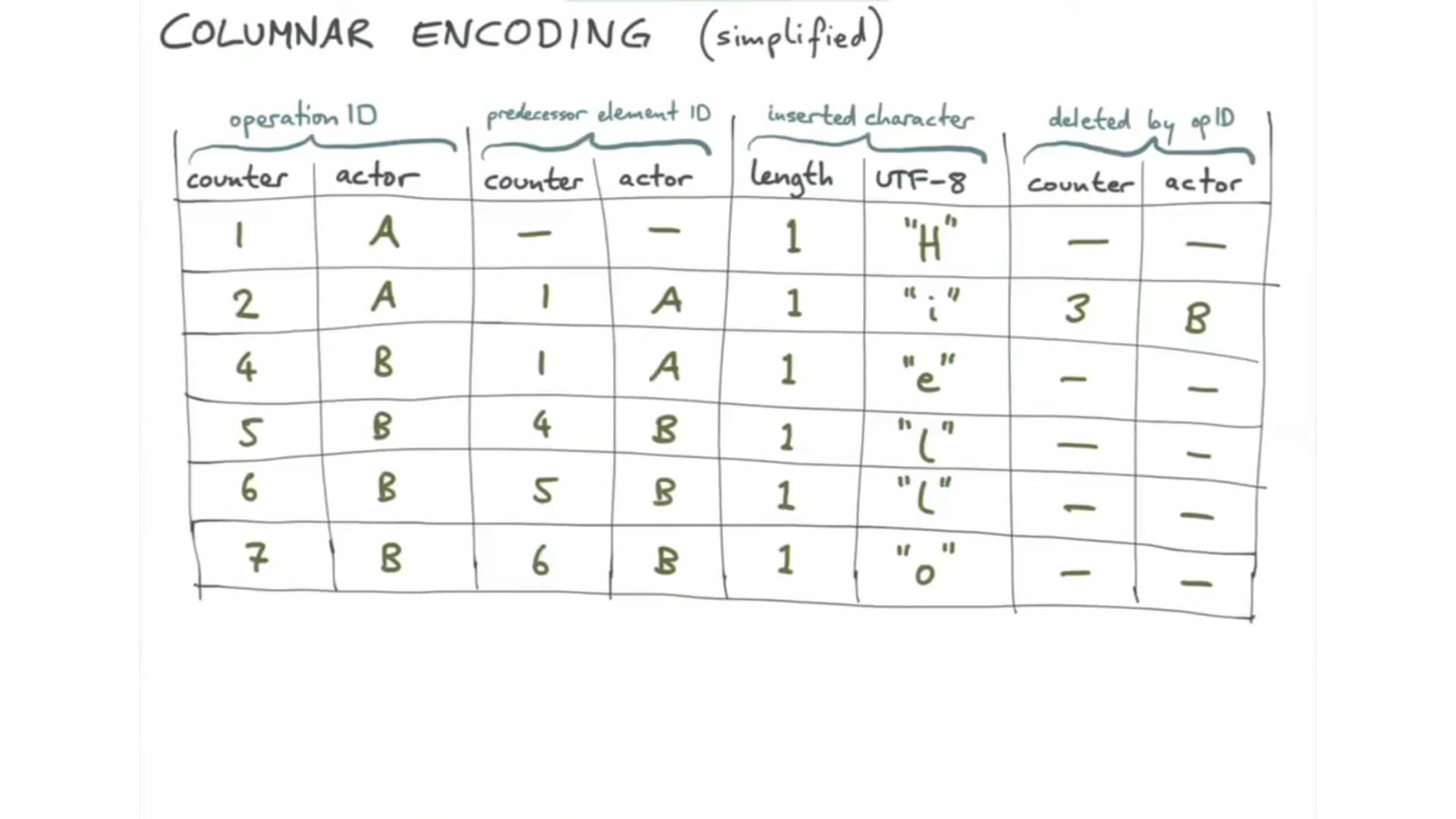
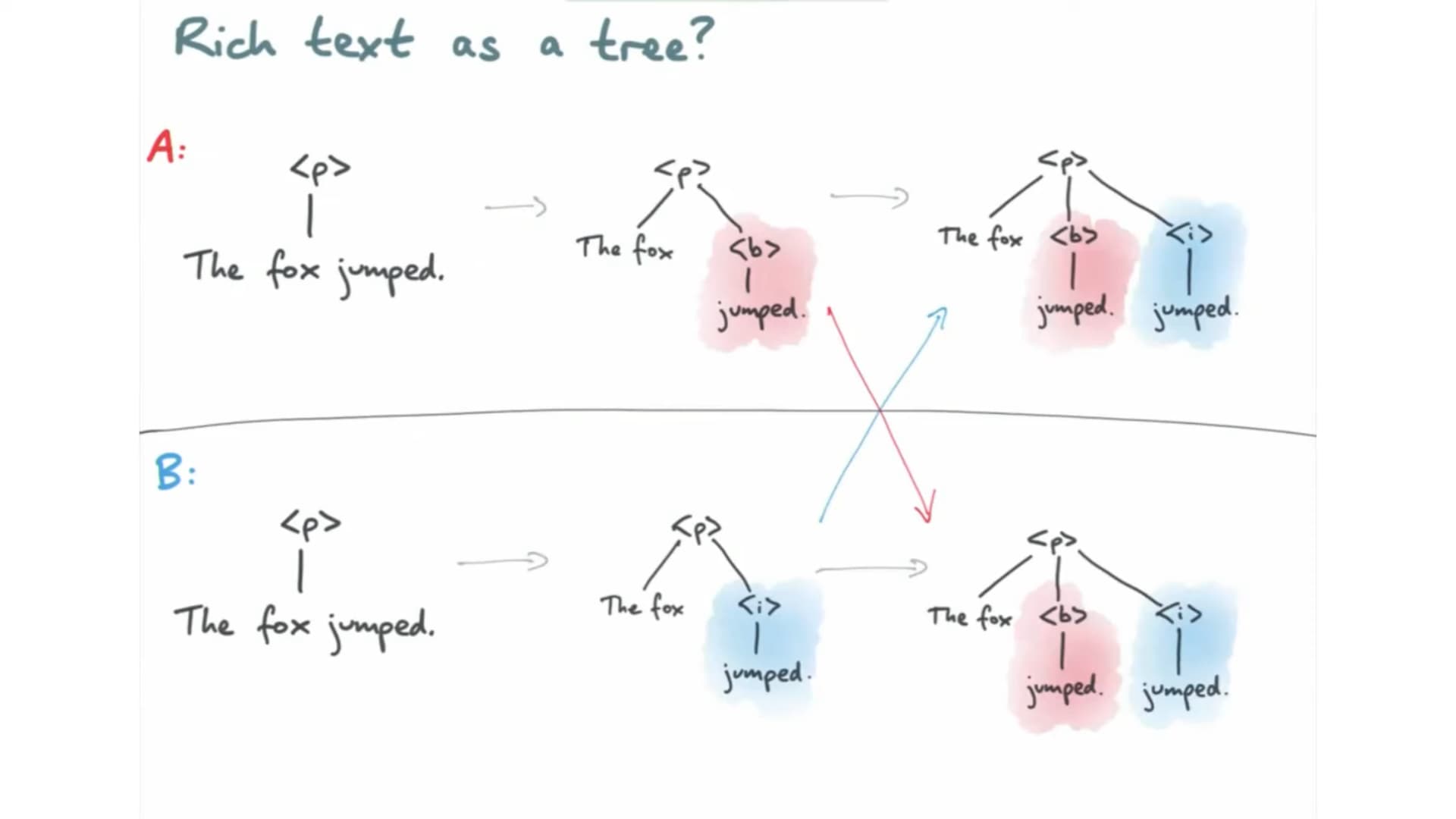
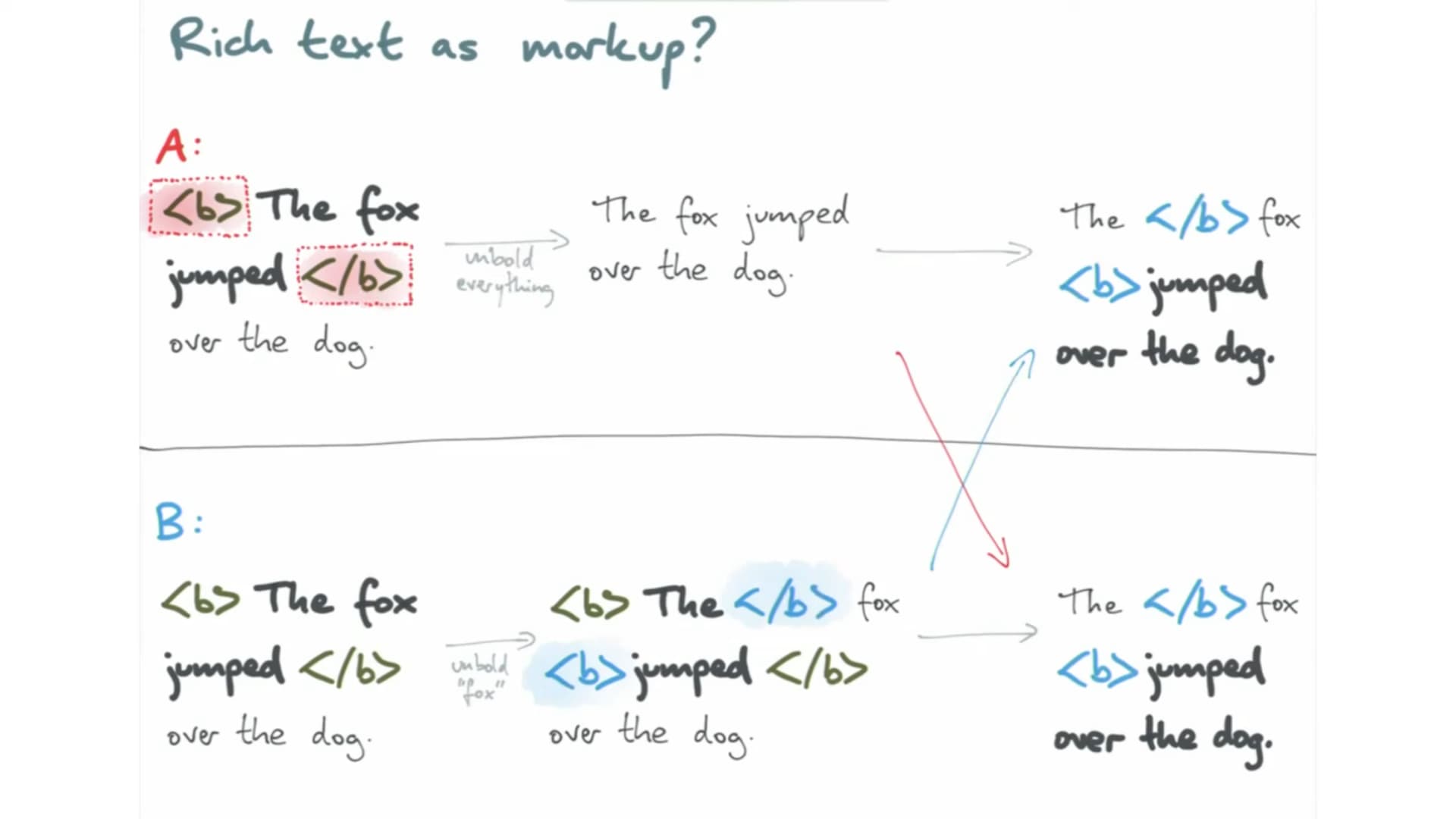
This is not an issue. Just want to pick the team's brain on what's the perspecti…ve on dealing with rich text elements with "layouts" like tables and lists. Kudos to the team, Peritext has come up with an efficient representation for holding both character data as well as formatting boundaries.
Handling block elements is a different beast altogether. I'll take tables for clarity as it's the most common block element, yet supports most complex operations.
Here are the options I see with Peritext's current representation.
1. Encode blocks as special control character. For example a table will have control characters for ```<table-start>, <table-end>, <row-start>, <column-start>```, .... etc.
```
[
{ char: "T", opId: "9@B", deleted: false, markOpsBefore: [
{
action: "addMark",
opId: "19@A",
start: { type: "before", opId: "9@B" },
end: { type: "before", opId: "10@B" },
markType: "bold"
}
] },
{ char: "t", opId: "1@A", deleted: true },
{ char: "h", opId: "2@A", deleted: false },
{ char: "e", opId: "3@A", deleted: false },
{ char: " ", opId: "4@A", deleted: false },
{ char: "f", opId: "5@A", deleted: false },
{ char: "o", opId: "6@A", deleted: false },
{ char: "x", opId: "7@A", deleted: false },
{ char: " ", opId: "10@B", deleted: false, markOpsBefore: [] },
{ char: "<table-start-char>", opId: "11@A", deleted: false },
//..... (rest of the table body with content interweaving table control characters)
{ char: "<table-end-char>", opId: "12@A", deleted: false },
]
```
- Makes formatting model play along nicely. But as quoted in the original article it takes significant complexity to tailor it for our desired outcomes. Keeps the base model simple but shifts the complexity to handling outcomes.
2. Encode tables as trees (i.e semantic JSON) and use automerge's/custom JSON capabilities.
```
[
{ char: "T", opId: "9@B", deleted: false, markOpsBefore: [
{
action: "addMark",
opId: "19@A",
start: { type: "before", opId: "9@B" },
end: { type: "before", opId: "10@B" },
markType: "bold"
}
] },
{ char: "t", opId: "1@A", deleted: true },
{ char: "h", opId: "2@A", deleted: false },
{ char: "e", opId: "3@A", deleted: false },
{ char: " ", opId: "4@A", deleted: false },
{ char: "f", opId: "5@A", deleted: false },
{ char: "o", opId: "6@A", deleted: false },
{ char: "x", opId: "7@A", deleted: false },
{ char: " ", opId: "10@B", deleted: false, markOpsBefore: [] },
{layout: "table", opId: "11@B", deleted: false, rows: [/* other table components */]} // special layout JSON
]
```
- Adds additional basic units to the model but plays along well with existing CRDTs that support trees/JSON. Doesn't mean handling outcomes is any easier. Might take significant complexity to deal with operations that might result in an un-renderable table structure.
None of the options might make sense actually. It's highly possible there are other better directions to take that handles semantic tree elements like tables and lists, which the team might already have a hang on. I'd be happy to wrap my head around what's cooking and maybe help in someway.
CRDTs for working with non-schematic JSON is fairly straightforward. CRDTs for schematic JSON like a SQL database is slightly tricky but the operation types (insert row, insert column, update cell) are too simple to warrant a complex solution. But tables in a WYIWYG editors are the most complex of them all with operations like cell-merge and cell-splitting. As far as I've studied none of the existing CRDT literature touches on this particular topic. Given Peritext's direction this project might be the only one, that throws light in this area.
")